%%capture
'''
(C) Copyright 2020-2025 Murilo Marques Marinho (murilomarinho@ieee.org)
This file is licensed in the terms of the
Attribution-NonCommercial-ShareAlike 4.0 International (CC BY-NC-SA 4.0)
license.
Derivative work of:
https://github.com/dqrobotics/learning-dqrobotics-in-matlab/tree/master/robotic_manipulators
Contributors to this file:
Murilo Marques Marinho (murilomarinho@ieee.org)
'''DQ8 Optimization-based Robot Control¶
I found an issue¶
Thank you! Please report it at https://
Introduction¶
In the last lesson, you learned the concept of task-space singularities and a particular way to address them.
In this lesson, we will revisit the topic of robot control using quadratic optimization formalism.
%%capture
%pip install dqrobotics quadprog dqrobotics-pyplot
%pip install dqrobotics quadprog dqrobotics-pyplot --break-system-packagesfrom math import pi
import numpy as np
from dqrobotics import *
from dqrobotics.utils import DQ_Geometry
from dqrobotics.robot_control import ControlObjective
from dqrobotics.robot_modeling import DQ_Kinematics
from dqrobotics_extensions.pyplot import plot
import matplotlib.pyplot as plt
plt.rcParams["animation.html"] = "jshtml" # Need to output animation's videos
import matplotlib.animation as anm
from functools import partial # Need to call functions correctly for matplotlib animationsNotation¶
Keep these in mind (we will also use this notation when writing papers for conferences and journals):
- : a quaternion. (Bold-face, lowercase character)
- : a dual quaternion. (Bold-face, underlined, lowercase character)
- : pure quaternions. They represent points, positions, and translations. They are quaternions for which .
- : unit quaternions. They represent orientations and rotations. They are quaternions for which .
- : unit dual quaternions. They represent poses and pose transformations. They are dual quaternions for which .
- : a Plücker line.
- : a plane.
- : real numbers.
- real vectors.
- real matrices.
Robot definition¶
The concepts of this lesson apply to any manipulator robot. However, to have a more concrete understanding using DQ Robotics, consider the same robot as used in the past lesson.
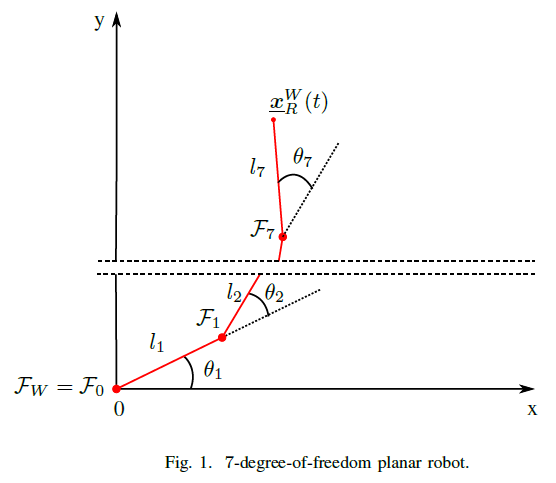
- Let the robot be a 7-DoF planar robot, as drawn in Fig.1.
- Let be the world-reference frame.
- Let represent the pose of the end effector.
- Let be composed of seven rotational joints that rotate about their z-axis, composed in the joint-space vector with for . The rotation of the reference frames of each joint coincides with the rotation of when . The lengths of the joints are .
- Consider that we can freely control the joint vector .
This robot can be modeled by the following class.
from seven_dof_planar_robot_dh import SevenDofPlanarRobotDH
help(SevenDofPlanarRobotDH.kinematics)Help on function kinematics in module seven_dof_planar_robot_dh:
kinematics()
Returns the kinematics of the SevenDoFPlanarRobot as DQ_SerialManipulatorDH.
Let us instantiate our robot as follows
seven_dof_planar_robot = SevenDofPlanarRobotDH.kinematics()A brief review of quadratic optimization¶
At some point in your education, you might have been introduced to optimization problems. There are many types of optimization problems, and in this lesson, we will address only two types, which are enough to solve a large class of robot control problems.
Unconstrained quadratic optimization¶
The first type is called unconstrained quadratic optimization
where is a quadratic objective function that depends on the current joint configuration. Note that it is called an optimization problem, and NOT an equation (note that there is no equality sign). In mathematical optimization terminology, is called the decision variable.
You can read that as “find all that minimize and return one of them as .” The solution for an unconstrained quadratic optimization problem can, in general, be found analytically. In this lesson we will call that minimizer as .
Quadratic programming¶
The second type of optimization problem that we will address is called quadratic programming (QP), which is a linearly constrained quadratic optimization problem, in the form
where and represent linear constraints related to the degrees-of-freedom of the robot. Note that we use and not because we are representing element-wise inequalities.
You can read that QP as “find all that minimize , subject to less or equal to , and return one of them as .” In general, numerical methods are required to obtain a solution for a QP. Similarly to the unconstrained case, in this lesson we will call that minimizer as .
The damped pseudo-inverse as the solution of an unconstrained quadratic optimization problem¶
In the last lesson, the meaning of the damping factor was introduced in the point-of-view of the SVD of the robot’s task Jacobian.
The damping factor can be trivially understood when we re-write the robot control problem in the following way
where is the task Jacobian for an DoF robot and an DoF task. In addition, is the proportional gain of the controller and is the task error. Lastly, is the damping factor.
Note that we are balancing two terms in the objective function. The first term, , will be high when the task error is high and zero when the task error is zero. The second term, , will penalize high joint velocities depending on the size of the damping factor. As we saw in practice in the last lesson, the damping factor is used as a term to balance task error convergence and the norm of the joint velocities.
Given that we have an unconstrained quadratic optimization problem which is, by definition, convex, the solution is straightforward. The optimum is where the first-order partial derivative of the objective function with respect to the decision variable equals to zero. Hence
Notice that this solution is exactly the same as the damped pseudo-inverse used in the last lesson.
Joint limits¶
Using unconstrained optimization to solve robot-control tasks is useful in some cases, but most tasks in practice have what we call hard limits. They are called that way in the sense that those limits are joint-space or task-space limits that cannot be trespassed. For instance, joint limits are a physical type of hard limit. The controller cannot command the robot to move over its joint limits.
When performing kinematic control, the decision variables are the joint velocities and not the joint positions. Therefore, we need to write the joint limits as a linear inequality that depends on the joint velocities.
Suppose that the lower joint limits are and the upper joint limits are . The most common way of implementing joint limits using a QP is as follows
where
and
where is a configurable gain. In general, we choose .
The main idea behind this constraint is to constrain the velocity of the joint in the direction of the joint limit.
DQ Robotics Example¶
To solve QPs as described in this lesson using DQ Robotics, use the following class
from dqrobotics.robot_control import DQ_ClassicQPController
help(DQ_ClassicQPController)Help on class DQ_ClassicQPController in module dqrobotics._dqrobotics._robot_control:
class DQ_ClassicQPController(DQ_QuadraticProgrammingController)
| Method resolution order:
| DQ_ClassicQPController
| DQ_QuadraticProgrammingController
| DQ_KinematicConstrainedController
| DQ_KinematicController
| pybind11_builtins.pybind11_object
| builtins.object
|
| Methods defined here:
|
| __init__(...)
| __init__(self: dqrobotics._dqrobotics._robot_control.DQ_ClassicQPController, arg0: dqrobotics._dqrobotics._robot_modeling.DQ_Kinematics, arg1: dqrobotics._dqrobotics._solvers.DQ_QuadraticProgrammingSolver) -> None
|
| compute_objective_function_linear_component(...)
| compute_objective_function_linear_component(self: dqrobotics._dqrobotics._robot_control.DQ_ClassicQPController, arg0: numpy.ndarray[numpy.float64[m, n]], arg1: numpy.ndarray[numpy.float64[m, 1]]) -> numpy.ndarray[numpy.float64[m, 1]]
|
| Compute the objective function.
|
| compute_objective_function_symmetric_matrix(...)
| compute_objective_function_symmetric_matrix(self: dqrobotics._dqrobotics._robot_control.DQ_ClassicQPController, arg0: numpy.ndarray[numpy.float64[m, n]], arg1: numpy.ndarray[numpy.float64[m, 1]]) -> numpy.ndarray[numpy.float64[m, n]]
|
| Compute symmetric matrix.
|
| ----------------------------------------------------------------------
| Methods inherited from DQ_QuadraticProgrammingController:
|
| compute_setpoint_control_signal(...)
| compute_setpoint_control_signal(self: dqrobotics._dqrobotics._robot_control.DQ_QuadraticProgrammingController, arg0: numpy.ndarray[numpy.float64[m, 1]], arg1: numpy.ndarray[numpy.float64[m, 1]]) -> numpy.ndarray[numpy.float64[m, 1]]
|
| Compute the setpoint control signal.
|
| compute_tracking_control_signal(...)
| compute_tracking_control_signal(self: dqrobotics._dqrobotics._robot_control.DQ_QuadraticProgrammingController, arg0: numpy.ndarray[numpy.float64[m, 1]], arg1: numpy.ndarray[numpy.float64[m, 1]], arg2: numpy.ndarray[numpy.float64[m, 1]]) -> numpy.ndarray[numpy.float64[m, 1]]
|
| Compute the tracking control signal.
|
| ----------------------------------------------------------------------
| Methods inherited from DQ_KinematicConstrainedController:
|
| set_equality_constraint(...)
| set_equality_constraint(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicConstrainedController, arg0: numpy.ndarray[numpy.float64[m, n]], arg1: numpy.ndarray[numpy.float64[m, 1]]) -> None
|
| Sets equality constraints.
|
| set_inequality_constraint(...)
| set_inequality_constraint(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicConstrainedController, arg0: numpy.ndarray[numpy.float64[m, n]], arg1: numpy.ndarray[numpy.float64[m, 1]]) -> None
|
| Sets inequality constraints.
|
| ----------------------------------------------------------------------
| Methods inherited from DQ_KinematicController:
|
| get_control_objective(...)
| get_control_objective(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController) -> dqrobotics._dqrobotics._robot_control.ControlObjective
|
| Gets the control objective
|
| get_damping(...)
| get_damping(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController) -> float
|
| Gets the damping.
|
| get_gain(...)
| get_gain(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController) -> float
|
| Gets the controller gain
|
| get_jacobian(...)
| get_jacobian(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: numpy.ndarray[numpy.float64[m, 1]]) -> numpy.ndarray[numpy.float64[m, n]]
|
| Gets the Jacobian
|
| get_last_error_signal(...)
| get_last_error_signal(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController) -> numpy.ndarray[numpy.float64[m, 1]]
|
| Gets the last error signal
|
| get_task_variable(...)
| get_task_variable(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: numpy.ndarray[numpy.float64[m, 1]]) -> numpy.ndarray[numpy.float64[m, 1]]
|
| Gets the task variable
|
| is_set(...)
| is_set(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController) -> bool
|
| Checks if the controller's objective has been set
|
| reset_stability_counter(...)
| reset_stability_counter(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController) -> None
|
| Resets the stability counter
|
| set_control_objective(...)
| set_control_objective(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: dqrobotics._dqrobotics._robot_control.ControlObjective) -> None
|
| Sets the control objective
|
| set_damping(...)
| set_damping(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: float) -> None
|
| Sets the damping.
|
| set_gain(...)
| set_gain(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: float) -> None
|
| Sets the controller gain
|
| set_primitive_to_effector(...)
| set_primitive_to_effector(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: dqrobotics._dqrobotics.DQ) -> None
|
| Sets the effector primitive
|
| set_stability_counter_max(...)
| set_stability_counter_max(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: int) -> None
|
| Sets the maximum of the stability counter
|
| set_stability_threshold(...)
| set_stability_threshold(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: float) -> None
|
| Sets the stability threshold
|
| set_target_primitive(...)
| set_target_primitive(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController, arg0: dqrobotics._dqrobotics.DQ) -> None
|
| Sets the target primitive
|
| system_reached_stable_region(...)
| system_reached_stable_region(self: dqrobotics._dqrobotics._robot_control.DQ_KinematicController) -> bool
|
| Checks if the controller has stabilized
|
| ----------------------------------------------------------------------
| Static methods inherited from pybind11_builtins.pybind11_object:
|
| __new__(*args, **kwargs) class method of pybind11_builtins.pybind11_object
| Create and return a new object. See help(type) for accurate signature.
To solve a QP, you have to choose the numerical solver that will be used by the controller. MATLAB has a solver in its optimization toolbox called “quadprog.” To use it, first instantiate the robot and the solver
from dqrobotics.solvers import DQ_QuadprogSolver
# Solver definition
qp_solver = DQ_QuadprogSolver()and then instantiate the controller and set the control objective, the gain, and the damping factor
# Controller definition
translation_controller = DQ_ClassicQPController(seven_dof_planar_robot, qp_solver)
translation_controller.set_control_objective(ControlObjective.Translation)
translation_controller.set_gain(10)
translation_controller.set_damping(1)Let us define the following joint limits
# Joint limits
q_minus = -(pi/8) * np.ones(7)
q_plus = (pi/8) * np.ones(7)
print(f"q_minus = {q_minus}")
print(f"q_plus = {q_plus}")q_minus = [-0.39269908 -0.39269908 -0.39269908 -0.39269908 -0.39269908 -0.39269908
-0.39269908]
q_plus = [0.39269908 0.39269908 0.39269908 0.39269908 0.39269908 0.39269908
0.39269908]
We define the other control-related variables as in the last lesson.
# Desired translation (pure quaternion)
td = 7 * j_
# Sampling time [s]
tau = 0.01
# Simulation time [s]
time_final = 4
# Initial joint values [rad]
q = np.zeros(7)
# Store the joint values
stored_q = []
# Translation controller loop.
for time in np.arange(0, time_final + tau,tau):
# Store q for posterior animation
stored_q.append(q)
# The linear inequalities depend on the current joint values, so we calculate them inside the control loop.
# Define the linear inequality matrix and the linear inequality vector
Wjl = np.vstack((-np.eye(7), np.eye(7)))
wjl = np.hstack((-1 * (q_minus-q), 1 * (q_plus-q)))
# We then add them to the controller using the following method
# Update the linear inequalities in the controller
translation_controller.set_inequality_constraint(Wjl, wjl)
# The rest of the control loop is unchanged with respect to prior lessons.
# Get the next control signal [rad/s]
u = translation_controller.compute_setpoint_control_signal(q, vec4(td))
# Move the robot
q = q + u * tauPlot related code with reusable functions animate_robot and setup_plot.
# Animation function
def animate_robot(n, robot, stored_q, xd):
dof = robot.get_dim_configuration_space()
plt.cla()
plot(robot, q=stored_q[n])
plot(xd)
plt.xlabel('x [m]')
plt.xlim([-dof, dof])
plt.ylabel('y [m]')
plt.ylim([-dof, dof])
ax = plt.gca()
ax.axes.zaxis.set_ticklabels([])
plt.title(f'Translation control time={time} s out of {time_final} s')
def setup_plot():
fig = plt.figure()
ax = plt.axes(projection='3d')
ax.set_proj_type('ortho')
ax.view_init(azim=0, elev=90) #https://stackoverflow.com/questions/33084853/set-matplotlib-view-to-be-normal-to-the-x-y-plane-in-python
return fig, ax
fig, ax = setup_plot()
anm.FuncAnimation(fig,
partial(animate_robot, robot=seven_dof_planar_robot, stored_q=stored_q, xd = 1 + 0.5*E_*td),
frames=len(stored_q))We can then verify that the joint limits have been kept.
fig = plt.figure()
for i in range(0, 7):
plt.subplot(3,3,i+1)
np_stored_q = np.array(stored_q)
plt.plot(np_stored_q[:,i])
plt.plot(np.ones(np_stored_q.shape[0]) * q_minus[i],'k')
plt.plot(np.ones(np_stored_q.shape[0]) * q_plus[i],'k')
plt.title(f'$q_{i}$')
plt.ylim([-1, 1])
plt.ylabel('[rad]')
plt.xlabel('Iteration')
fig.tight_layout()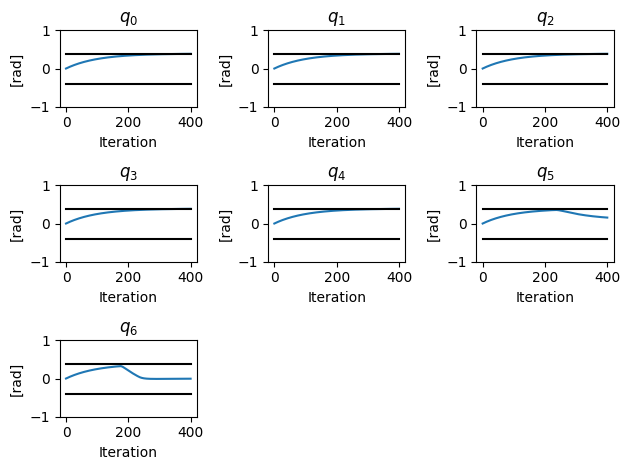
Note that the robot was unable to reach the desired task-space translation due to the joint limits, as shown by the black lines representing the joint limits. This is exactly what we wanted: a controller that will get as close as possible to the target while maintaining the robot’s joint limits.
Vector-field inequalities: task-space collision avoidance¶
We have just now seen how to use linear inequalities to prevent the robot from trespassing on its joint limits. The joint limits are one of the few applications of joint-space constraints. In most cases, we are interested in having task-space constraints. That is, constraints that are defined at the task space. The difficulty in doing so is writing the task-space constraint as linear constraints in joint space.
An effective way of doing so is called vector-field inequalities (VFIs), presented in detail in the following paper.
[1] Marinho, M. M; Adorno, B. V; Harada, K.; and Mitsuishi, M. Dynamic Active Constraints for Surgical Robots using Vector Field Inequalities. IEEE Transactions on Robotics (T-RO), 35(5): 1166–1185. October 2019.
The VFIs are described in detail in [1], so to simplify the discussion for this lesson, consider the (signed) distance to be the relation between some entity in the robot, such as a point, line, or plane, and another entity in the workspace.
Keeping the robot entity outside a restricted zone¶
Consider the situation of keeping the robot entity outside a restricted zone. We define the distance error in such a way that the distance error is positive whenever the robot is outside the restricted zone, zero when at the border, and negative when inside the restricted zone. The distance error is then , where is the safe distance, that we suppose to be constant in time in this lesson.
To obtain the general formulation of the VFIs, we start with the following task-space inequality, that will keep our robot outside a restricted zone
where is a proportional gain. To be used in our QP, we need to re-write this as a joint-space linear constraint, which is what the VFI method does.
The VFIs are then given by
Given that the safe distance is constant in time. Now, notice that if the distance depends on the joint values, we can find a distance Jacobian such that the following holds
where is the distance Jacobian for that specific pair of entities.
The linear constraint for that pair of entities, with respect to the joint velocities, then becomes
That constraint can be re-written to be compatible with our QP definition as
Keeping the robot entity inside a safe zone¶
The reasoning is basically the same of the restricted zone case, but the distance error is redefined as . This causes the linear constraint to change to
Square distances instead of distances¶
Calculating the distance Jacobians of the distance of some primitives introduces algorithmic singularities, as shown in [2]. To handle that problem, we often calculate the Jacobian of the square distance instead [1]. The notation for square distances is the upper-case letter .
[2] Marinho, M. M; Adorno, B. V; Harada, K.; and Mitsuishi, M. Active Constraints using Vector Field Inequalities for Surgical Robots. In 2018 IEEE International Conference on Robotics and Automation (ICRA), pages 5364–5371, May 2018.
Distance Jacobians¶
In lesson 4, we learned about distance functions using dual quaternions, and in lesson 6 you learned how to calculate a few Jacobians. Using that knowledge, it is easy to calculate the distance Jacobians related to the distance functions.
We will go through how to calculate all the distance Jacobians described in [1] using DQ Robotics, but we will skip most of the mathematical derivations because they are already described in detail in the paper.
Preliminaries¶
To calculate the distance Jacobian, the following two definitions are useful.
First, the cross-product between can be mapped into using the operator , as follows [1, Eq. (3)]
,
Second, the time derivative of the squared norm of a time-varying quaternion is given by [1, Eq. (4)]
Two new task Jacobians are also needed. Similarly, to how we obtained the translation, rotation, and pose Jacobians, we can also obtain the Jacobians related to lines and planes in the robot.
Line Jacobian¶
Suppose that we want the Jacobian related to line with direction that passes through the end-effector. The line will be given by [1, Eq. (24)]
Given our definition of line, we have the following [1, Eq. (28)]
Using DQ Robotics, we can obtain the line Jacobian as follows
# Get robot's pose and pose Jacobian
x = seven_dof_planar_robot.fkm(q)
Jx = seven_dof_planar_robot.pose_jacobian(q)
# Define the line direction
lv = k_
# Get the line Jacobian
Jlv = DQ_Kinematics.line_jacobian(Jx, x, lv)
print(f"Jlv = {Jlv}")Jlv = [[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 -5.55111512e-17 -5.55111512e-17 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 7.45479631e-01 -1.81048005e-01 -8.97954928e-01 -1.29989544e+00
-1.32780652e+00 -9.77586757e-01 -4.86904393e-01]
[ 5.67013315e+00 5.29390644e+00 4.59673754e+00 3.68107176e+00
2.68146135e+00 1.74479379e+00 8.73455272e-01]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]]
where is the line Jacobian. It can be decomposed into
where is composed of the first four rows of the line Jacobian, which are related to the direction of the line. In addition, is composed of the last four rows of the line Jacobian, which are related to the line moment.
Plane Jacobian¶
Lastly, the Jacobian related to the plane in the end-effector with normal will be given by
where
and
# Get robot's pose and pose Jacobian
x = seven_dof_planar_robot.fkm(q)
Jx = seven_dof_planar_robot.pose_jacobian(q)
# Define the line direction
piv = k_
# Get the line Jacobian
Jpiv = DQ_Kinematics.plane_jacobian(Jx, x, piv)
print(f"Jpiv = {Jpiv}")Jpiv = [[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 -5.55111512e-17 -5.55111512e-17 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]
[ 0.00000000e+00 0.00000000e+00 0.00000000e+00 0.00000000e+00
0.00000000e+00 0.00000000e+00 0.00000000e+00]]
Point-to-point distance Jacobian¶
Let the translation of the robot’s point entity be and the position of a point in the workspace be . The squared-distance between those two points is, as mentioned in lesson 4, is [1, Eq. (21)]
The derivative of the squared-distance is, therefore [1, Eq. (22)]
This means that the point-to-point distance Jacobian is given by
Using DQ Robotics, it can be calculated as
# Point in the workspace
p = 2 * j_
# Get robot's pose and pose Jacobian
x = seven_dof_planar_robot.fkm(q)
Jx = seven_dof_planar_robot.pose_jacobian(q)
# Get the robot's translation and translation Jacobian
t = translation(x)
Jt = DQ_Kinematics.translation_jacobian(Jx, x)
# Get the distance Jacobian
Jp_p = DQ_Kinematics.point_to_point_distance_jacobian(Jt, t, p)
print(f"Jp_p = {Jp_p}")Jp_p = [[ -2.98191852 -9.22193941 -13.44477671 -15.02990676 -13.74440306
-9.77716359 -4.87629414]]
Point-to-line distance Jacobian¶
Let be a line entity in the workspace. The square distance between a point entity in the robot and that line is [1, Eq. (29)]
The point-to-line distance Jacobian is, therefore [1, Eq. (32)]
Using DQ Robotics, it can be calculated as
# Line in the workspace
l_dq = j_
# Get robot's pose and pose Jacobian
x = seven_dof_planar_robot.fkm(q)
Jx = seven_dof_planar_robot.pose_jacobian(q)
# Get the robot's translation and translation Jacobian
t = translation(x)
Jt = DQ_Kinematics.translation_jacobian(Jx, x)
# Get the distance Jacobian
Jt_l = DQ_Kinematics.point_to_line_distance_jacobian(Jt, t, l_dq)
print(f"Jt_l = {Jt_l}")Jt_l = [[-8.45393754 -7.89299883 -6.85354842 -5.48832804 -3.99794964 -2.60141647
-1.30228623]]
Line-to-point distance Jacobian¶
Let be a line entity related to the robot. The square distance between that line and a point in the workspace is given by [1, Eq. (33)]
The line-to-point distance Jacobian is a bit more involved, as described in [1, Eq. (34)].
Using DQ Robotics, it can be calculated as
# Point in the workspace
p = 2 * j_
# Get robot's pose and pose Jacobian
x = seven_dof_planar_robot.fkm(q)
Jx = seven_dof_planar_robot.pose_jacobian(q)
# Get the robot's translation and translation Jacobian
t = translation(x)
Jt = DQ_Kinematics.translation_jacobian(Jx, x)
# Define the direction of the line passing through the end-effector and get
# the line Jacobian
lv = k_
Jl = DQ_Kinematics.line_jacobian(Jx, x, lv)
# Get the robot's rotation
r = rotation(x)
# Get the robot line
lv_dq = Ad(r,lv) + E_*cross(t, Ad(r,lv))
# Get the distance Jacobian
Jlv_p = DQ_Kinematics.line_to_point_distance_jacobian(Jl, lv_dq, p)
print(f"Jlv_p = {Jlv_p}")Jlv_p = [[ -2.98191852 -9.22193941 -13.44477671 -15.02990676 -13.74440306
-9.77716359 -4.87629414]]
Line-to-line distance Jacobian¶
Suppose that we want to calculate the Jacobian that relates the distance between a line entity in the robot, , and a line in the workspace The mathematical derivation is described in detail in [1, Eq. (48)]. To obtain the line-to-line distance Jacobian using DQ Robotics, we do
# Line in the workspace
l_dq = j_
# Get robot's pose and pose Jacobian
x = seven_dof_planar_robot.fkm(q)
Jx = seven_dof_planar_robot.pose_jacobian(q)
# Get the robot's translation
t = translation(x)
# Define the direction of the line passing through the end-effector and get
# the line Jacobian
lv_e = k_ # From the point-of-view of the end-effector
Jl = DQ_Kinematics.line_jacobian(Jx, x, lv_e)
# Get the robot's rotation
r = rotation(x)
# Get the robot line direction
lv = Ad(r,lv) # (in the point-of-view of the base)
lv_dq = lv + E_*cross(t, lv) # (in the point-of-view of the base)
# Get the distance Jacobian
Jlv_p = DQ_Kinematics.line_to_line_distance_jacobian(Jl, lv_dq, l_dq)
print(f"Jlv_p = {Jlv_p}")Jlv_p = [[-8.45393754 -7.89299883 -6.85354842 -5.48832804 -3.99794964 -2.60141647
-1.30228623]]
Point-to-plane distance Jacobian¶
Let be a plane entity in the workspace. The signed distance between the robot’s translation, , and the plane, in the point of view of the plane is given by [1, Eq. (57)].
The point-to-plane distance Jacobian will therefore be given by [1, Eq. (59)]
Using DQ Robotics, it can be obtained as
# Define the plane in the workspace
pi_w = i_
# Get robot's pose and pose Jacobian
x = seven_dof_planar_robot.fkm(q)
Jx = seven_dof_planar_robot.pose_jacobian(q)
# Get the robot's translation and translation Jacobian
t = translation(x)
Jt = DQ_Kinematics.translation_jacobian(Jx, x)
# Get the distance Jacobian
Jt_pi = DQ_Kinematics.point_to_plane_distance_jacobian(Jt, t, pi_w)
print(f"Jt_pi = {Jt_pi}")Jt_pi = [[-5.67013315 -5.29390644 -4.59673754 -3.68107176 -2.68146135 -1.74479379
-0.87345527]]
Plane-to-point distance Jacobian¶
Let be a plane entity in the robot. The signed distance between the robot’s plane entity, , and a point in the workspace, , in the point of view of the plane is given by [1, Eq. (57)]
The plane-to-point distance Jacobian will be given by
Using DQ Robotics, it can be obtained as
# Point in the workspace
p = 2 * j_
# Get robot's pose and pose Jacobian
x = seven_dof_planar_robot.fkm(q)
Jx = seven_dof_planar_robot.pose_jacobian(q)
# Get the robot's translation and translation Jacobian
t = translation(x)
Jt = DQ_Kinematics.translation_jacobian(Jx, x)
# Get the robot rotation (to calculate the plane)
r = rotation(x)
# Get the robot's plane
n_pi_v_e = i_ # Plane's normal with respect to the end-effector
Jpi = DQ_Kinematics.plane_jacobian(Jx, x, n_pi_v_e)
# Get the distance Jacobian
Jpi_p = DQ_Kinematics.plane_to_point_distance_jacobian(Jpi, p)
print(f"Jpi_p = {Jpi_p}")Jpi_p = [[-0.97380879 0.0186581 0.98429883 1.78121758 2.29231136 2.44247761
2.43814707]]
Vector-field inequalities in action¶
We saw how to calculate several types of distances and distance Jacobians. Now we need to put this knowledge to good use.
Preventing collision with walls¶
Suppose that there is one wall above and one wall below our 7-DoF planar robot, and we want to prevent any collisions between the robot and those walls.
The top wall is given by
pi_top = -j_ - E_ * 2and the bottom wall is given by
pi_bottom = j_ + -E_ * 2Note that the normals of those planes are pointing towards the robot. This is important because it means that the distance of any point of the robot will be positive with respect to those planes. Mistaking the direction of the plane’s normal is a common error, so be careful.
Let us plot the two walls.
fig = plt.figure()
ax = plt.axes(projection='3d')
plot(pi_top, plane=True, scale=14)
plot(pi_bottom, plane=True, scale=14)
plt.title('Plane constraints')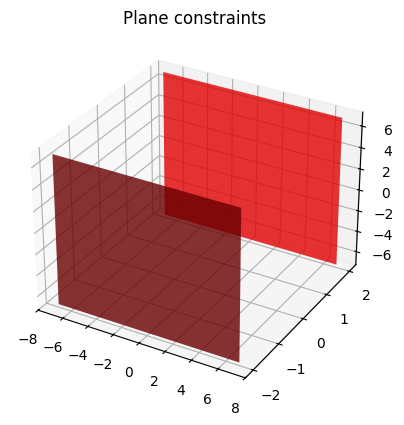
To prevent the collision between the robot and those walls, one strategy is to create one point-to-plane constraint for each of the robot’s joints with respect to those planes. This corresponds to a total of fourteen linear constraints.
Using DQ Robotics, they can be implemented as follows.
# Define a list of planes
plane_list = [pi_top, pi_bottom]
# Define the robot
seven_dof_planar_robot = SevenDofPlanarRobotDH.kinematics()
# Solver definition
qp_solver = DQ_QuadprogSolver()
# Controller definition
translation_controller = DQ_ClassicQPController(seven_dof_planar_robot, qp_solver)
translation_controller.set_control_objective(ControlObjective.Translation)
translation_controller.set_gain(10)
translation_controller.set_damping(1)
# VFI gain
eta_d = 1
# Desired translation (pure quaternion)
td = 7 * j_
# Sampling time [s]
tau = 0.01
# Simulation time [s]
final_time = 4
# Initial joint values [rad]
q = 0.01 * np.ones(7)
# Store the signals
stored_q = []
# Translation controller loop.
for time in np.arange(0, time_final + tau,tau):
# Store q for posterior animation
stored_q.append(q)
# The inequality matrix and vector
W = None
w = None
n = seven_dof_planar_robot.get_dim_configuration_space()
for joint_counter in range(0, n):
# Get the pose Jacobian and pose of the current joint
Jx = seven_dof_planar_robot.pose_jacobian(q, joint_counter)
x = seven_dof_planar_robot.fkm(q, joint_counter)
# Get the translation Jacobian and the translation of the current
# joint
Jt = DQ_Kinematics.translation_jacobian(Jx, x)
t = translation(x)
for plane_counter in range (0, len(plane_list)):
# Get the current plane
workspace_plane = plane_list[plane_counter]
# Calculate the point-to-plane distance Jacobian
# We have to augment the Jp_pi with zeros
Jp_pi = np.hstack((DQ_Kinematics.point_to_plane_distance_jacobian(Jt, t, workspace_plane), np.zeros((1, n-joint_counter-1))))
# Calculate the point-to-plane distance
dp_pi = DQ_Geometry.point_to_plane_distance(t, workspace_plane)
# Wq <= w
if W is None:
W = -Jp_pi
else:
W = np.vstack((W, -Jp_pi))
if w is None:
w = np.array(eta_d * dp_pi)
else:
w = np.vstack((w, eta_d * dp_pi))
# Update the linear inequalities in the controller
translation_controller.set_inequality_constraint(W, w)
# Get the next control signal [rad/s]
u = translation_controller.compute_setpoint_control_signal(q, vec4(td))
# Move the robot
q = q + u * tauPlot related code with reusable functions animate_robot_with_planes and setup_plot.
# Animation function
def animate_robot_with_planes(n,
robot,
stored_q,
xd,
pi_top,
pi_bottom):
dof = robot.get_dim_configuration_space()
plt.cla()
plot(robot, q=stored_q[n])
plot(xd)
plot(pi_top, plane=True, scale=14)
plot(pi_bottom, plane=True, scale=14)
plt.xlabel('x [m]')
plt.xlim([-dof, dof])
plt.ylabel('y [m]')
plt.ylim([-dof, dof])
ax = plt.gca()
ax.axes.zaxis.set_ticklabels([])
plt.title(f'Translation control time={time} s out of {time_final} s')
def setup_plot():
fig = plt.figure()
ax = plt.axes(projection='3d')
ax.set_proj_type('ortho')
ax.view_init(azim=0, elev=90) #https://stackoverflow.com/questions/33084853/set-matplotlib-view-to-be-normal-to-the-x-y-plane-in-python
return fig, ax
fig, ax = setup_plot()
anm.FuncAnimation(fig,
partial(animate_robot_with_planes,
robot=seven_dof_planar_robot,
stored_q=stored_q,
xd = 1 + 0.5*E_*td,
pi_top = pi_top,
pi_bottom = pi_bottom),
frames=len(stored_q),
interval=int(tau*1000))Entry-sphere constraint¶
A widespread type of constraint in minimally invasive surgery is the entry-sphere constraint. Suppose there is an incision in the skin of the patient, positioned at
p = 5 * j_Let us define the sphere to have a radius of 0.25 m. That is, we choose
d_safe = 0.25Moreover, let us attach to our planar robot a 2-meter-long shaft whose axis is collinear with the axis of the last link, as follows
# Define the initial joint configurations [rad]
q = (pi / 8.) * np.ones(7)
# Define the robot
seven_dof_planar_robot = SevenDofPlanarRobotDH.kinematics()
# Add the shaft
seven_dof_planar_robot.set_effector(1 + 0.5 * E_ * (2 * i_))1 + E*(1i)Let us control the robot to the following desired translation
# Desired translation
td = -1 * i_ + 4 * j_In a way that the shaft never goes outside the entry-sphere. Using DQ Robotics, this can be done as follows
# Solver definition
qp_solver = DQ_QuadprogSolver()
# Controller definition
translation_controller = DQ_ClassicQPController(seven_dof_planar_robot, qp_solver)
translation_controller.set_control_objective(ControlObjective.Translation)
translation_controller.set_gain(10)
translation_controller.set_damping(1)
# VFI gain
eta_d = 1
# Sampling time [s]
tau = 0.01
# Simulation time [s]
final_time = 4
# Store the signals
stored_q = []
# Translation controller loop.
for time in np.arange(0, time_final + tau,tau):
# Store q for posterior animation
stored_q.append(q)
# Get the pose Jacobian and the pose
Jx = seven_dof_planar_robot.pose_jacobian(q)
x = seven_dof_planar_robot.fkm(q)
# Get the line Jacobian for the x-axis
Jl = DQ_Kinematics.line_jacobian(Jx, x, i_)
# Get the line with respect to the base
t = translation(x)
r = rotation(x)
l = Ad(r, i_)
l_dq = l + E_ * cross(t, l)
# Get the line-to-point distance Jacobian
Jl_p = DQ_Kinematics.line_to_point_distance_jacobian(Jl, l_dq, p)
# Get the line-to-point square distance
Dl_p = DQ_Geometry.point_to_line_squared_distance(p, l_dq)
# Get the distance error
D_safe = d_safe ** 2
D_tilde = D_safe - Dl_p
# The inequality matrix and vector
W = np.array(Jl_p)
w = np.array([eta_d * D_tilde])
# Update the linear inequalities in the controller
translation_controller.set_inequality_constraint(W, w)
# Get the next control signal [rad/s]
u = translation_controller.compute_setpoint_control_signal(q, vec4(td))
# Move the robot
q = q + u * tauWe define a plot function animate_robot_with_entry_sphere and reuse setup_plot defined earlier.
# Animation function
def animate_robot_with_entry_sphere(n,
robot,
tau,
stored_q,
xd,
p_dq):
dof = robot.get_dim_configuration_space()
plt.cla()
plot(robot, q=stored_q[n])
plot(xd)
plot(p_dq)
plt.xlabel('x [m]')
plt.xlim([-dof, dof])
plt.ylabel('y [m]')
plt.ylim([-dof, dof])
ax = plt.gca()
ax.axes.zaxis.set_ticklabels([])
plt.title(f'Translation control time={n*tau} s out of {time_final} s')
fig, ax = setup_plot()
anm.FuncAnimation(fig,
partial(animate_robot_with_entry_sphere,
robot=seven_dof_planar_robot,
tau=tau,
stored_q=stored_q,
xd = 1 + 0.5*E_*td,
p_dq = 1 + 0.5*E_*p),
frames=len(stored_q),
interval=int(tau*1000))Homework¶
Create a class called VS050RobotDH that represents the Denso VS050 robot, whose DH parameters are described in the following table and is composed entirely of revolute joints. (Remember lesson 6)
End-effector: attach to the robot a 20cm-long-shaft along the axis of the last joint.
Initial configuration:
- Create a file called
vs050_plane_constraints.pyand do the following:- Create a translation controller with . Choose the other controller parameters so that the control is smooth (see this and prior lessons for examples).
- Create 6 planes centered around the point , so that all normals are pointed inwards, to make a 5 cm cube. (remember lesson 4)
- During control, use point-to-plane VFIs to keep the tooltip always inside the cubic region.
- Move the end-effector, in order, to the following four desired positions , for 4 simulation-time seconds each.
- Plot the task error in one figure
- Plot the distance of the end-effector to all the six planes using subplots in another figure.
- Create a file called
vs050_entry_sphere_constraint.pyand do the following:- Create a translation controller with . Choose the other controller parameters so that the control is smooth (see this and prior lessons for examples).
- Consider the entry-sphere to be centered at . Consider the entry sphere to have a radius of 5 mm.
- During control, use a line-to-point VFI to keep the shaft always inside the entry-sphere.
- Move the end-effector, in order, to the following four desired positions , for 4 simulation-time seconds each.
- Plot the task error in one figure
- Plot the distance of the shaft to the center of the entry-sphere in another figure.