License: CC-BY-NC-SA 4.0
Author: Murilo M. Marinho (murilo
Pre-requisites for the learner¶
The user of this notebook is expected to have prior knowledge in
All the content and pre-requisites of lessons 1, 2, 3, and 4.
I found an issue¶
Thank you! Please report it at https://
Latex Macros¶
\providecommand{\myvec}[1]{{\mathbf{\boldsymbol{{#1}}}}}
\providecommand{\mymatrix}[1]{{\mathbf{\boldsymbol{{#1}}}}}Package installation¶
%%capture
%pip install numpy matplotlib
%pip install numpy matplotlib --break-system-packagesImports¶
%matplotlib inline
import numpy as np
import matplotlib.pyplot as plt
from math import pi, sin, cos2 DoF planar robot (RR)¶
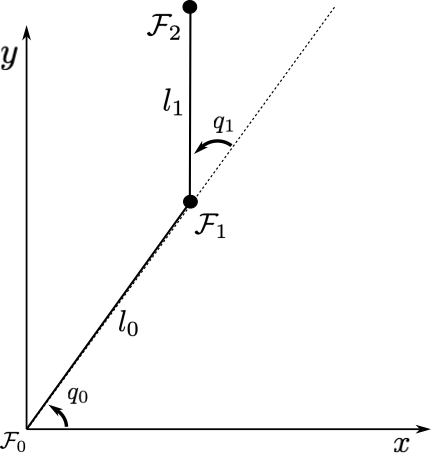
For the 2-DoF planar robot shown in the figure, let , , , be the parameters to calculate
that is, the forward kinematics model of the 2 DoF planar manipulator with configuration space given by
and given the analytical Jacobian below
where
in which , , and are, respectively, the -axis position, the -axis position, and the -axis angle of . Notice that .
Consider the forward kinematics model calculated as in the past lesson¶
This means that, from inspection,
With those, we can obtain the task space values with a function called planar_robot_fkm so that it can be easily reused
def planar_robot_fkm(q):
"""
q: The configuration space values in radians.
returns the x, this, the current task space value where x = [p_x p_y phi_z]^T.
"""
l_0 = 0.2 # The robot parameters. They don't change in time, so they are constant here.
l_1 = 0.1
q_0 = q[0] # Just to make it more readable.
q_1 = q[1]
p_x = l_0 * cos(q_0) + l_1 * cos(q_0 + q_1)
p_y = l_0 * sin(q_0) + l_1 * sin(q_0 + q_1)
phi_z = q_0 + q_1
return np.array([p_x,
p_y,
phi_z])Consider the analytical Jacobian¶
We first calculate the Jacobian by hand, because programatically there’s nothing for you to do yet. As we did in the previous tutorial, here is the Jacobian
We transform this Jacobian calculation into the function planar_robot_jacobian shown below
def planar_robot_jacobian(q):
"""
q: The configuration space values in radians.
returns the 3x2 Jacobian mapping [q_0 q_1]^T to [px py phi_z]^T.
"""
l_0 = 0.2 # The robot parameters. They don't change in time, so they are constant here.
l_1 = 0.1
q_0 = q[0] # Just to make it more readable.
q_1 = q[1]
J_1_1 = -l_0 * sin(q_0) - l_1 * sin(q_0 + q_1)
J_1_2 = -l_1 * sin(q_0 + q_1)
J_2_1 = l_0 * cos(q_0) + l_1 * cos(q_0 + q_1)
J_2_2 = l_1 * cos(q_0 + q_1)
J_3_1 = 1
J_3_2 = 1
return np.array(
[[J_1_1, J_1_2],
[J_2_1, J_2_2],
[J_3_1, J_3_2]]
)Kinematic Control¶
1. Define an error function¶
We usually use
that can be implemented as the function get_error below
def get_error(x, xd):
"""In this case, we use the difference as the error.
x: current task-space vector.
xd: desired task-space vector.
"""
return x - xd2. Define the control loop¶
We resort to the following control law
that can be easily implemented. Notice that we can resort to np.linalg.pinv() to perform the pseudo inversion. According to its documentation, it implements the Moore-Penrose pseudo-inversion based on the Singular Value Decomposition of all “large” singular values.
For the control loop itself, we use all previous functions. The idea here is to show that the norm of the error decreases with the control action. The desired task space vector will not always be achievable. Nonetheless, we can show, as below, that the control action reduces the task-space error, .
Let be the controller gain, be the sampling time, and . In addition, let the manipulator start at with .
eta = 0.5 # Controller proportional gain
T = 0.001 # Sampling time
# Define initial values for the joint positions
q_0 = 0.0
q_1 = 0.0
q = np.array([q_0,
q_1])
# A desired task-space value, defined by the problem at hand
xd = np.array([0.1,
0.1,
pi/10])
print(f"xd = {xd}")
# Define a stop criteria, in this case let's control for 10 seconds
t = 0 # Current time
# Lists to store the value of each control iteration
x_tilde_norm_list = []
t_list = []
while t < 10:
# Calculate task-space value, x
x = planar_robot_fkm(q)
# Calculate task-space error, x_tilde
x_tilde = get_error(x, xd)
# Get the Jacobian
J = planar_robot_jacobian(q)
# Invert the Jacobian, for example, with numpy's implementation of it
J_inv = np.linalg.pinv(J)
# Calculate the control action
u = -eta * J_inv @ x_tilde
## Store values in the list so that we can print them later
x_tilde_norm_list.append(np.linalg.norm(x_tilde))
t_list.append(t)
## Variable updated for the next loop
q = q + u * T # Update law using the sampling time
t = t + T xd = [0.1 0.1 0.31415927]
Optional: Print the data¶
To help visualise the behavior of the controller, you can optionally plot the data. These data show that with the defined parameters the qualitative behavior is very close to exponential decay.
However the error does not converge to zero, meaning that the manipulator did not reach its target. Indeed, this is usually the case when the target is outside the reach of the manipulator or all task-space desired values cannot be simultenously satisfied.
plt.plot(t_list,x_tilde_norm_list)
plt.title('(RR) Error exponential decay visualization (Moore-Penrose)')
plt.xlabel("Time [s]")
plt.ylabel("$||\\tilde{ \\bf{x} } (t) ||$")
plt.show()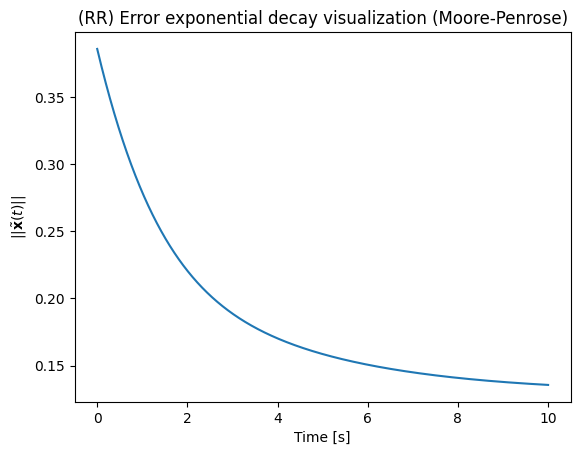
Alternative Jacobian Inversion Strategies¶
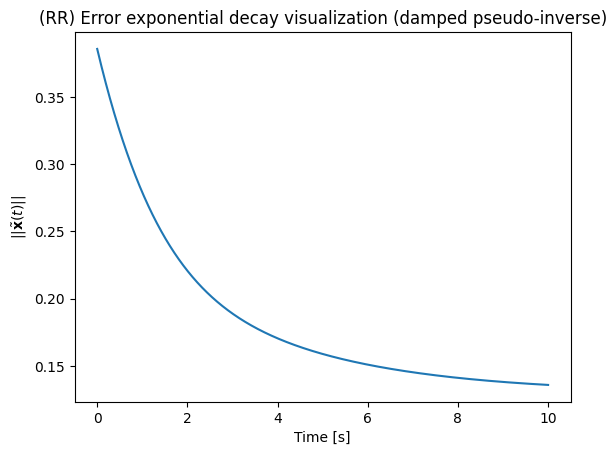
The SVD-based Moore-Penrose pseudo-invese is a common strategy for matrix inversion. It is important to notice, however, that is is not the only one. In addition, it is not always the best choice for robot control.
Another common strategy is the so-called damped pseudo-inverse, described below. It is usually the easiest choice to embbed robustness to singularities in the controller.
defined in the function damped_pseudo_inverse() below in which we call as the variable damping
def damped_pseudo_inverse(A: np.array, damping: float = 0.01):
"""Calculates the damped pseudo inverse of A"""
if damping == 0:
raise Exception(f"Damping is {damping} but should be different from zero")
return A.T @ np.linalg.inv(A @ A.T + (damping ** 2) * np.eye(A.shape[0]))with that, our controller becomes, changing only the inversion strategy,
eta = 0.5 # Controller proportional gain
T = 0.001 # Sampling time
# Define initial values for the joint positions
q_0 = 0.0
q_1 = 0.0
q = np.array([q_0,
q_1])
# A desired task-space value, defined by the problem at hand
xd = np.array([0.1,
0.1,
pi/10])
print(f"xd = {xd}")
# Define a stop criteria, in this case let's control for 10 seconds
t = 0 # Current time
# Lists to store the value of each control iteration
x_tilde_norm_list = []
t_list = []
while t < 10:
# Calculate task-space value, x
x = planar_robot_fkm(q)
# Calculate task-space error, x_tilde
x_tilde = get_error(x, xd)
# Get the Jacobian
J = planar_robot_jacobian(q)
# Invert the Jacobian using the damped pseudo-inverse
J_inv = damped_pseudo_inverse(J)
# Calculate the control action
u = -eta * J_inv @ x_tilde
## Store values in the list so that we can print them later
x_tilde_norm_list.append(np.linalg.norm(x_tilde))
t_list.append(t)
## Variable updated for the next loop
q = q + u * T # Update law using the sampling time
t = t + T
# (Optional) plot the data
plt.plot(t_list,x_tilde_norm_list)
plt.title('(RR) Error exponential decay visualization (damped pseudo-inverse)')
plt.xlabel("Time [s]")
plt.ylabel("$||\\tilde{ \\bf{x} } (t) ||$")
plt.show()xd = [0.1 0.1 0.31415927]
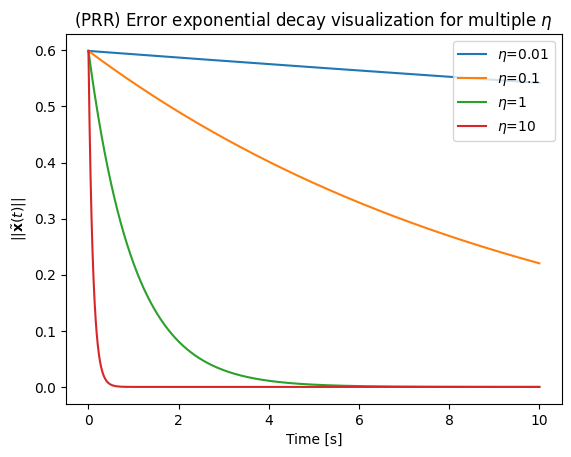
Convergence rate of discrete-time systems¶
Although we usually attempt to find such that, the error converges exponentially. This means that, in the right conditions, we will have a convergence
in continuous time, hence the convergence depends only on .
However, given that our implementation is in discrete time, the convergence is affected by our sampling time, . In practice, we set as the fastest sampling time that can be achieved by the hardware, e.g. the robot controller. In many cases, this is about 1 milisecond in pratice.
The effect on the convergence for different can be seen, computationally, below
etas = [0.01, 0.1, 1, 10] # Different gains to iterate over the same control goals
T = 0.001 # Sampling time
# A desired task-space value, defined by the problem at hand
xd = np.array([0.1,
0.1,
pi/10])
print(f"xd = {xd}")
# Lists to store the value of each control iteration
x_tilde_norm_list = []
t_list = []
u_norm_list = []
# Run the controller again for each gain
for i in range(0, len(etas)):
# Define a stop criteria, in this case let's control for 10 seconds
t = 0 # Current time
eta = etas[i]
# Define initial values for the joint positions
q_0 = 0.0
q_1 = 0.0
q = np.array([q_0,
q_1])
x_tilde_norm_list.append([])
t_list.append([])
u_norm_list.append([])
while t < 10:
# Calculate task-space value, x
x = planar_robot_fkm(q)
# Calculate task-space error, x_tilde
x_tilde = get_error(x, xd)
# Get the Jacobian
J = planar_robot_jacobian(q)
# Invert the Jacobian using the damped pseudo-inverse
J_inv = damped_pseudo_inverse(J)
# Calculate the control action
u = -eta * J_inv @ x_tilde
## Store values in the list so that we can print them later
x_tilde_norm_list[i].append(np.linalg.norm(x_tilde))
t_list[i].append(t)
u_norm_list[i].append(np.linalg.norm(u))
## Variable updated for the next loop
q = q + u * T # Update law using the sampling time
t = t + T
plt.plot(t_list[i],x_tilde_norm_list[i], label=f"$\\eta$={eta}")
plt.title('(RR) Error exponential decay visualization for multiple $\\eta$')
plt.legend(loc="upper right")
plt.xlabel("Time [s]")
plt.ylabel("$||\\tilde{ \\bf{x} } (t) ||$")
plt.show()xd = [0.1 0.1 0.31415927]
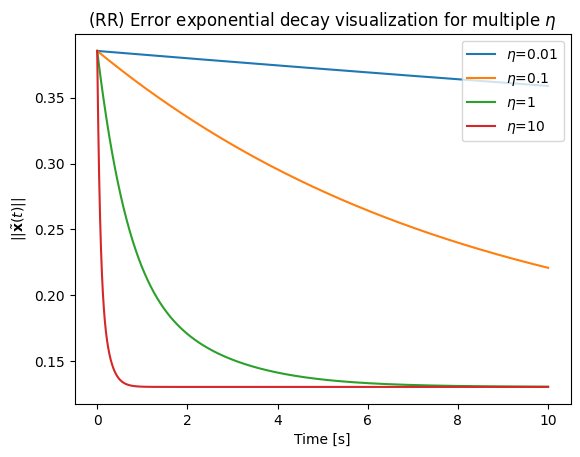
Alright, then why don’t we just choose the largest ?¶
Engineering is the art of trade-off. Whenever we have a large , that means the configuration-space velocities will comparatively be higher.
Using our example, we can see that the control signal norm is heavily affected by . Therefore, for feasibility, it is important to keep the so that the system can handle it. In fact, gains that are too high are one of the major risks that can break robots or hurt people when real hardware is used without the proper safeguards.
# Run the controller again for each gain
for i in range(0, len(etas)):
eta=etas[i]
plt.plot(t_list[i],u_norm_list[i], label=f"$\\eta$={eta}")
plt.title('(RR) Control signal norm for different $\\eta$')
plt.legend(loc="upper right")
plt.xlabel("Time [s]")
plt.ylabel("$||u (t) ||$")
plt.show()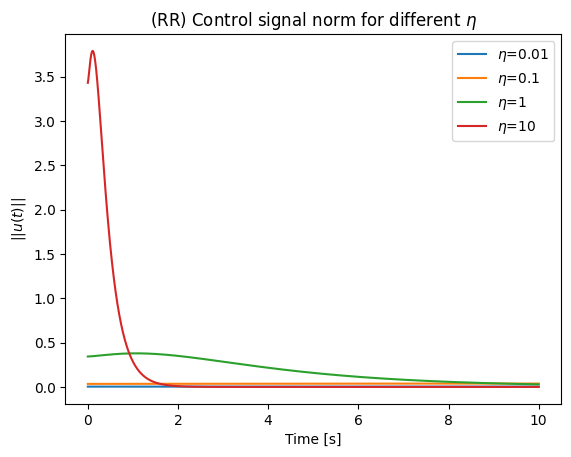
3 DoF Planar Robot (PRR)¶
As you noticed from the previous discussion, what is important for any new robot after you understand these concepts are
Defining a task space, , that correctly represents the task (and manipulator if applicable).
Obtaining the Forward Kinematics Model (FKM) that maps the configuration space, , to the task space.
Obtaining the analytical Jacobian so that the kinematic control can be applied.
The kinematic control itself, aside from dimensions, does not need to change in general.
For instance, we can even solve with no diagram as long as this information is given. Consider an PRR manipulator with configuration space
And link lenghts .
Task Space & Forward Kinematics Model (FKM)¶
Let
The forward kinematics of this manipulator is therefore given by
Because this robot is planar, the following task space is necessary and sufficient to fully describe the reacheable space
The values can be obtained from inspection of ,
which means that the FKM, , in this case is equivalent to
def planar_robot_prr_fkm(q: np.array) -> np.array:
"""
q: The configuration space values in radians.
returns the x, this, the current task space value where x = [p_x p_y phi_z]^T.
"""
l_0 = 0.2 # The robot parameters. They don't change in time, so they are constant here.
l_1 = 0.1
l_2 = 0.3
q_0 = q[0] # Just to make it more readable.
q_1 = q[1]
q_2 = q[2]
s1 = sin(q_1)
c1 = cos(q_1)
s12 = sin(q_1 + q_2)
c12 = cos(q_1 + q_2)
p_x = (l_0 + q_0) + l_1*c1 + l_2*c12
p_y = l_1*s1 + l_2*s12
phi_z = q_1 + q_2
return np.array([p_x,
p_y,
phi_z])def planar_robot_prr_jacobian(q):
"""
q: The configuration space values in radians.
returns the 3x3 Jacobian mapping [q_0 q_1 q_2]^T to [px py phi_z]^T.
"""
l_0 = 0.2 # The robot parameters. They don't change in time, so they are constant here.
l_1 = 0.1
l_2 = 0.3
q_0 = q[0] # Just to make it more readable.
q_1 = q[1]
q_2 = q[2]
s1 = sin(q_1)
c1 = cos(q_1)
s12 = sin(q_1 + q_2)
c12 = cos(q_1 + q_2)
J_1_1 = 1
J_2_1 = 0
J_3_1 = 0
J_1_2 = -l_1*s1 - l_2*s12
J_2_2 = l_1*c1 + l_2*c12
J_3_2 = 1
J_1_3 = -l_2*s12
J_2_3 = l_2*c12
J_3_3 = 1
return np.array(
[[J_1_1, J_1_2, J_1_3],
[J_2_1, J_2_2, J_2_3],
[J_3_1, J_3_2, J_3_3]]
)Kinematic Control¶
With this, a similar control as before, but changing the FKM and Jacobian can be easily achieved. We change only
The configuration space in lines 20 to 25.
planar_robot_prr_fkmin line 33planar_robot_prr_jacobianin line 37.
etas = [0.01, 0.1, 1, 10] # Different gains to iterate over the same control goals
T = 0.001 # Sampling time
# A desired task-space value, defined by the problem at hand
xd = np.array([0.1,
0.1,
pi/10])
print(f"xd = {xd}")
# Lists to store the value of each control iteration
x_tilde_norm_list = []
t_list = []
u_norm_list = []
# Run the controller again for each gain
for i in range(0, len(etas)):
# Define a stop criteria, in this case let's control for 10 seconds
t = 0 # Current time
eta = etas[i]
# Define initial values for the joint positions
q_0 = 0.0
q_1 = 0.0
q_2 = 0.0
q = np.array([q_0,
q_1,
q_2])
x_tilde_norm_list.append([])
t_list.append([])
u_norm_list.append([])
while t < 10:
# Calculate task-space value, x
x = planar_robot_prr_fkm(q)
# Calculate task-space error, x_tilde
x_tilde = get_error(x, xd)
# Get the Jacobian
J = planar_robot_prr_jacobian(q)
# Invert the Jacobian using the damped pseudo-inverse
J_inv = damped_pseudo_inverse(J)
# Calculate the control action
u = -eta * J_inv @ x_tilde
## Store values in the list so that we can print them later
x_tilde_norm_list[i].append(np.linalg.norm(x_tilde))
t_list[i].append(t)
u_norm_list[i].append(np.linalg.norm(u))
## Variable updated for the next loop
q = q + u * T # Update law using the sampling time
t = t + T
plt.plot(t_list[i],x_tilde_norm_list[i], label=f"$\\eta$={eta}")
plt.title('(PRR) Error exponential decay visualization for multiple $\\eta$')
plt.legend(loc="upper right")
plt.xlabel("Time [s]")
plt.ylabel("$||\\tilde{ \\bf{x} } (t) ||$")
plt.show()xd = [0.1 0.1 0.31415927]